Storage infrastructure
Ransomwares are a major threat for companies. Let’s get prepared before the Splash screen pops up. ![]()
Data storage background
First of all, let’s review the basics of data storage technologies.
Storage infrastructure technologies
Storage media use different technologies to store data:
- Magnetic: Hard Disk Drives (HDD) or magnetic tapes

- Optical: CD-R, DVD-R, Blu-ray

- Semiconductor: Solid-State Drive (SSD), USB…
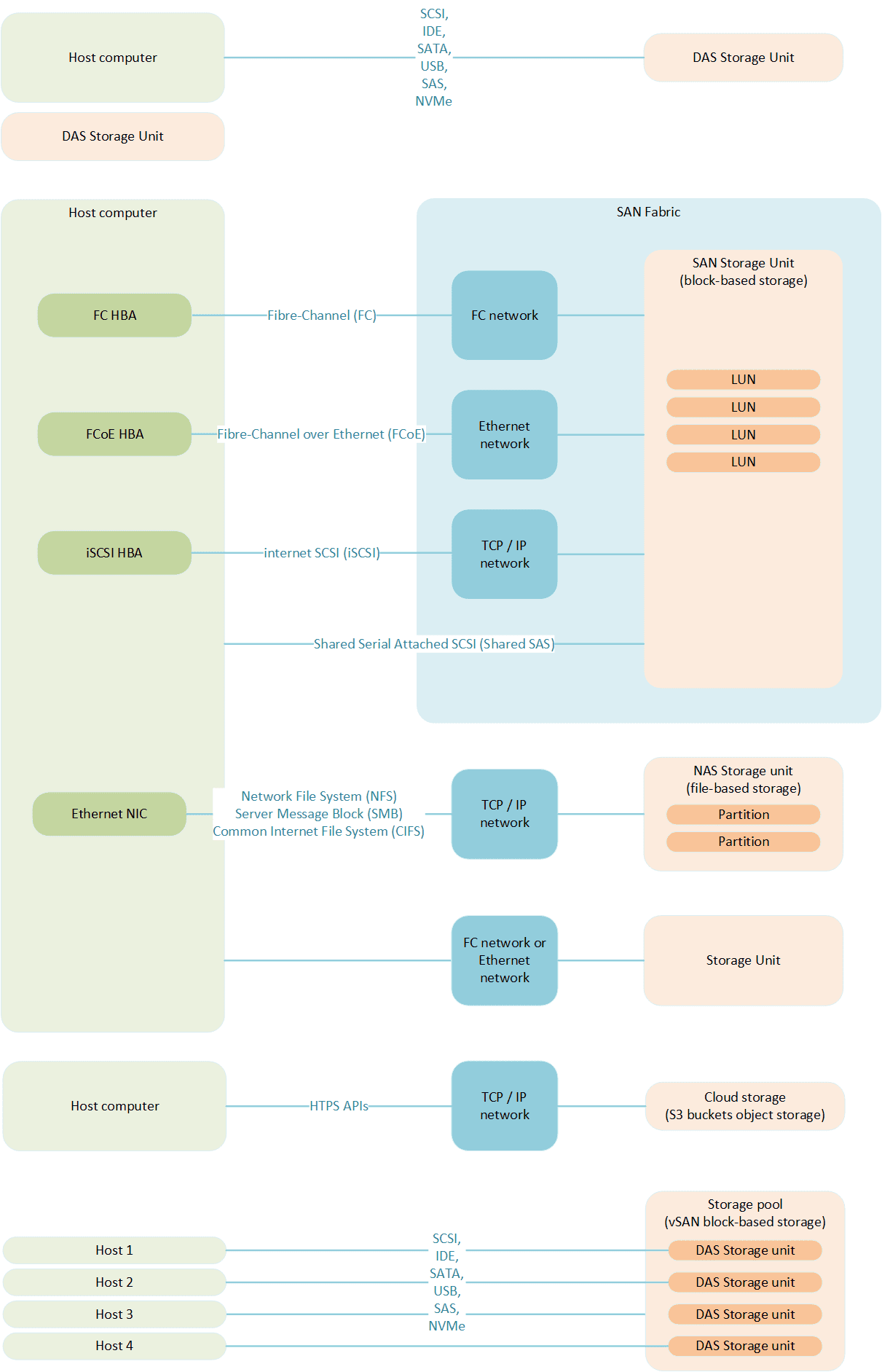
Storage technologies can be identified based on the location of the storage resource:
- Direct-attached storage (DAS): internal storage of the computer (attached to a bus), or external storage directly attached to a port (serial, USB). Such technology tend to create SPOF, and does not support multiple connections.
- Network-Attached Storage (NAS): storage devices connected with a common existing network (storage resource is just a node in the LAN).
-
Storage Area Network (SAN): storage devices connected with a dedicated high-speed storage network.

- Cloud storage: data hosted by a CSP, and accessed through APIs.
- Hyper-Converged Storage: the individual DAS storage of each host within the Hyper-Converged Infrastructure (HCI) are virtualized to build up a common storage pool.
Storage technologies can also be identified based on the storage type:
-
File storage: storage resources are presented as files in a file system (usually used in NAS technologies).

- Block storage: storage resources are presented as fixed-size blocks, wrongly referred to as a Logical Unit Number (LUN) (usually used in SAN technologies).
- Object storage: storage resources are presented as flexible-size buckets, identified by their OID.
Note: SQL / NoSQL databases use a higher level of abstraction independent from the underlying storage type.
Virtual Machines storage
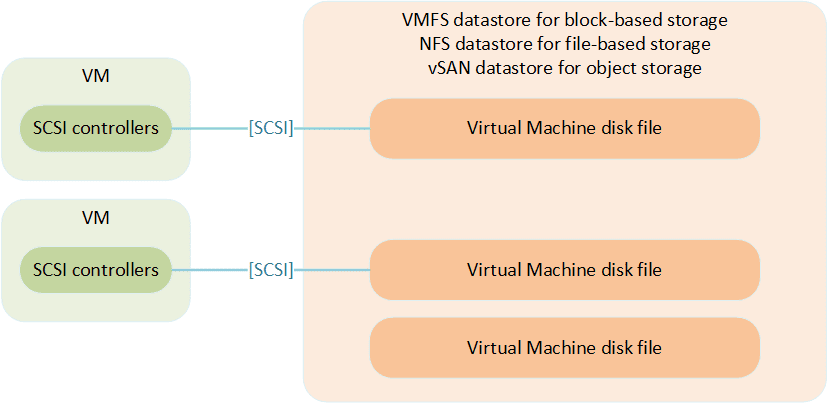
Let’s make a quick digest about Virtual Machines storage. VMs are basically a set of files, and are therefore easy to copy, move, archive… The Virtual Machine Disk file (vmdk) is the file format for the VM hard disk drive. The VMDK files are stored in datastores. In the case of block storage, the hypervisor formats a LUN with the Virtual Machine File System (VMFS) to create a VMFS datastore. For file storage, the hypervisor simply mounts the partition of the file storage. The VM only issues SCSI commands to communicate with its virtual disk, which are encapsulated into other protocols depending on the storage technology.
Data categorization and lifecycle
No let’s focus on the only topic that truly matters: data. The storage strategy relies on data categorization:
- Sensitivity (public, internal, confidential…)

- Frequency of access (every second, day, month… for cold / hot data)
- Environment (development, testing, operational…)
This classification determines the Confidentiality, Integrity and Availability requirements applicable, during all the lifecycle:
- At rest

- In transit
- In use
- Traveling outside of the security perimeter (download, USB shipping…)
Data availability
Let’s focus on data availability. The purpose is to be prepared for Disaster Recovery (DR). The recovery policies shall specify:
- The Recovery Time Objective (RTO): maximum acceptable amount of time for regaining data access after an incident.

- The Recovery Point Objective (RPO): maximum acceptable amount of data loss after an incident, expressed as an amount of time.
Note: The strategy shall not only focus on malware, but also on hardware failures, or unintentional errors leading to data deletion. Preventive hardware maintenance reduces the threat of hardware failure. ![]()
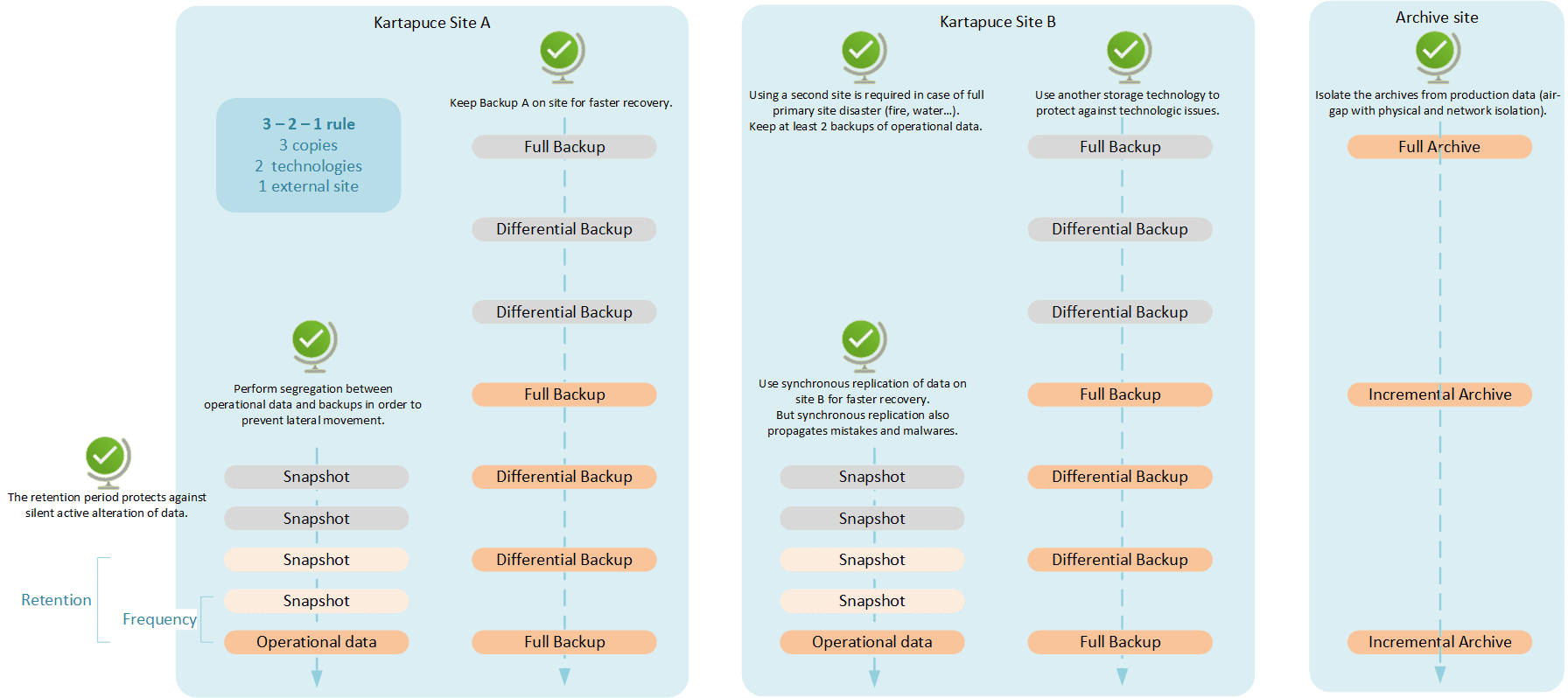
Several operations can help mitigating the risk of data loss:
- replication: synchronous (real-time) copy of data on another location for faster recovery.
- point-in-time copies: versioning of data for easy roll-back to a given point in time.
- backups: periodic copies of data in case of operational data loss.
- archives: long-term storage of a subset of data, especially for legal concerns.
Note: ![]()
- Snapshots are NOT backups! Snapshots only copy the data that changed from the base source data, in order to perform storage-efficient versioning of data. But if the base disk (“.vmdk” and “-base.vmdk” files), or an intermediate snapshot (“-00000X.vmdk” and “-00000X-delta.vmdk” files) is corrupted, then all the operational data is lost.
- RAID mirroring is NOT backup! Redundant Array of Independent Disks (RAID) is a storage virtualization technology used to improve read / writes performances. But it does not provide enough hardware independence to be used for backups.
- Synchronization services are NOT backups! OneDrive and Google Drive aim at storing and synchronizing files, in order to make them available from multiple clients. But if a file is deleted or encrypted, it is going to be replicated by the service.

Data confidentiality
Now let’s focus on another major topic of data security: confidentiality! Data at rest confidentiality is achieved with symmetric encryption, with algorithms such as AES.
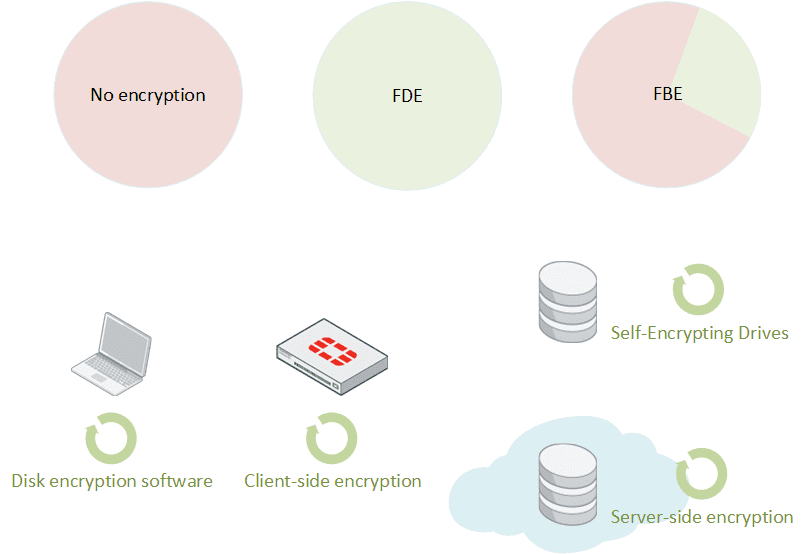
Encryption technologies can be identified based on the scope of encrypted data:
- No encryption: If your hardware is stolen, things might get dirty!
-
Full Disk Encryption (FDE): On-the-fly encryption of the entire disk, including system partitions. It secures against hardware loss or theft, but that’s an all or nothing solution.
-
File-Based Encryption (FBE): Encryption of individual files, or repositories within the file-system. It provides additional granularity, but its administration might become a tedious task.
Encryption technologies can also be identified based on the location of encryption:
- Disk encryption software: In most use-case for individual laptops, encryption is provided by a software deployed on the host, such as Bitlocker, FileVault, VeraCrypt…
- Self-encrypting Drives (SED): In the context of a SAN or a NAS, the micro-controllers of the Storage array can automatically encrypt any data stored on the hardware.
- Server-side encryption for cloud storage: the data is only protected at rest at its destination. Most of the time, the CSP is accountable for key management.
- Client-side encryption for cloud storage: In order to ensure end-to-end confidentiality of the data both at rest and in transit, the customer might prefer to perform encryption before sending its data to the CSP, with customer-managed keys.
The integrity of data is obtained through continuous verification of stored data (data scrubbing), and also after any storage operation (backups).
Note: Performing regular training and testing is fundamental for being prepared in case of an incident. ![]()
Note: Based on original learning material from NIST SP 800-209 documentation Security Guidelines for Storage Infrastructure, and from VMware engineers.